- Solutions

- Industries
Check out the best opportunities for:














The promise of multi-agent systems in GenAI is massive: distributed, intelligent agents collaborating in parallel to complete complex tasks. But while the theory sounds compelling, reality hits hard, especially in production.
Most failures in multi-agent systems have nothing to do with the intelligence of the agents. The real problem? Orchestration, control, and verification.
This post unpacks the six most common failure patterns, why they happen, and what enterprise-grade multi-agent systems do differently to prevent them.
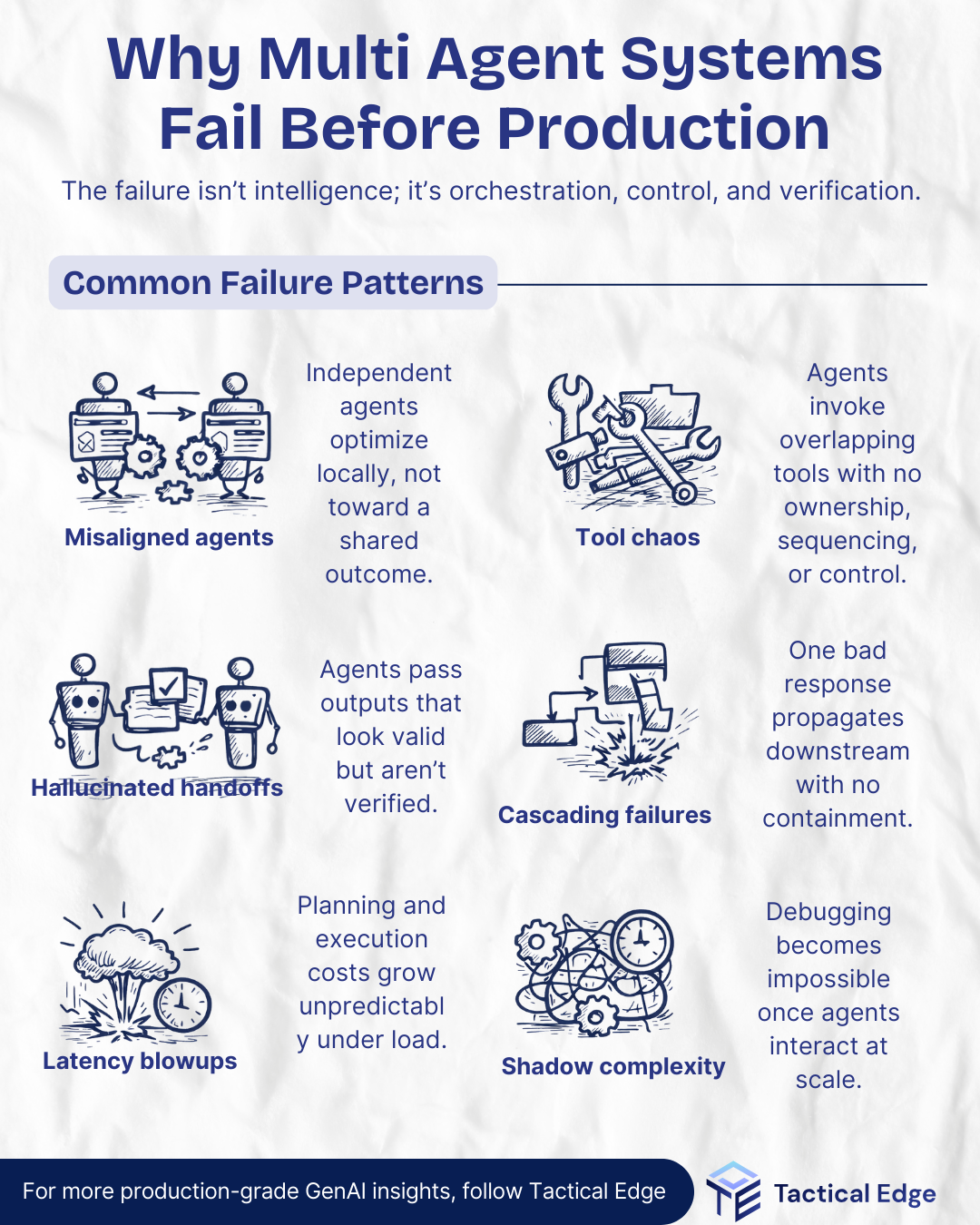
One of the earliest failure modes in multi-agent systems shows up when independent agents pursue local goals without considering the larger system.
They might each be optimizing their part, but the sum of the parts leads nowhere useful.
Example: An agent that prioritizes speed chooses a low-latency API, while another values completeness and waits for deeper context. The result? Conflicting outputs that never converge.
Use a shared task schema. This defines input contracts, expected outputs, and agent responsibilities. It gives every agent a north star.
A production-grade multi-agent system makes this schema part of the design, not an afterthought.
In fast-moving builds, agents often call whatever tools they can access. At first, this looks efficient. But as the tool stack grows, agents begin stepping on each other.
One agent might invoke a summarizer, while another sends the same input to a classifier, both unaware of each other.
Establish centralized tool routing. Enterprise multi-agent systems make tool access explicit and observable, so nothing gets lost in the fog.
Tool chaos is a scaling killer. Without visibility, teams spend hours debugging interactions between systems that were never designed to talk.
This one’s dangerous. Agents pass outputs downstream that look valid, but aren’t.
Imagine an agent hands off an address it "parsed" from a form. Downstream systems assume it's verified. It's not. Errors cascade silently.
Use circuit breakers. They verify outputs at each step and isolate failures before they spread.
In complex multi-agent systems, hallucinated handoffs introduce hidden brittleness. A system that looks stable may actually be standing on sand.
Without safeguards, a single bad agent response can ripple through the entire chain.
A malformed record in Step 2 causes rejection in Step 4, which causes confusion in Step 6… and no one knows where it began.
Insert circuit breakers and end-to-end observability. Make it possible to trace, pause, or block a bad output before it poisons downstream logic.
Mature multi-agent systems are built in failure pathways. They don’t just assume agents will behave; they design around when they won’t.
In testing, everything runs fine. In production? The system crawls.
What took 3 seconds in staging now takes 17 seconds in prod—with occasional 45-second spikes.
Bake in budgeted execution. That means planning for latency, cost, and concurrency from day one, not retrofitting after things break.
Enterprise multi-agent systems treat latency as a design variable, not a surprise. This unlocks predictability and scale.
As agents grow in number, so does the invisible complexity between them.
Devs spend hours trying to reproduce a failure that only happens under specific chains of events… and it’s never the same twice.
Adopt end-to-end observability. You need full trace logs, decision graphs, and replays to debug complex multi-agent system flows.
Shadow complexity is where multi-agent systems die quietly. Not with explosions—but with silence, confusion, and hours of root-cause analysis.
Failures are inevitable. But the best systems are designed to fail intelligently. Here’s how production-ready multi-agent systems prevent chaos:

Defines clear contracts between agents, what goes in, what comes out, and who owns what.
Ensures every tool call is explicit, observable, and governed.
Validates and contains failures before they spread through the system.
Latencies, costs, and thread use are designed in, not discovered later.
Every decision, source, and output is traceable and replayable.
These aren’t just features. They’re requirements for any multi-agent system that expects to survive in production.
The real challenge in multi-agent systems isn’t making smart agents. It’s building a smart system around them.
Control beats chaos. Observability beats guessing. And orchestration, not raw intelligence, is what gets you to production.
If you're designing for scale, start with these enterprise guardrails. Treat multi-agent systems like living ecosystems, not pipelines. That’s how they thrive.

Check our latest featured and latest blog post from our team at Tactical Edge AI
Accelerate value from data, cloud, and AI.
Copyright © Tactical Edge All rights reserved
.svg)
.svg)
.svg)
%20(1).webp)








